Evaluation quick start
This quick start will get you up and running with our evaluation SDK and Experiments UI.
1. Install Dependencies
- Python
- TypeScript
pip install -U langsmith openai pydantic
yarn add langsmith openai zod
2. Create an API key
To create an API key head to the Settings page. Then click Create API Key.
3. Set up your environment
- Shell
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
# The example uses OpenAI, but it's not necessary in general
export OPENAI_API_KEY=<your-openai-api-key>
4. Create a dataset
- Python
- TypeScript
from langsmith import Client
client = Client()
# Create inputs and reference outputs
examples = [
(
"Which country is Mount Kilimanjaro located in?",
"Mount Kilimanjaro is located in Tanzania.",
),
(
"What is Earth's lowest point?",
"Earth's lowest point is The Dead Sea.",
),
]
# Programmatically create a dataset in LangSmith
dataset = client.create_dataset(
dataset_name="Sample dataset", description="A sample dataset in LangSmith."
)
inputs = [{"question": input_prompt} for input_prompt, _ in examples]
outputs = [{"answer": output_answer} for _, output_answer in examples]
# Add examples to the dataset
client.create_examples(inputs=inputs, outputs=outputs, dataset_id=dataset.id)
import { Client } from "langsmith";
const client = new Client();
// Create inputs and reference outputs
const examples: [string, string][] = [
[
"Which country is Mount Kilimanjaro located in?",
"Mount Kilimanjaro is located in Tanzania.",
],
[
"What is Earth's lowest point?",
"Earth's lowest point is The Dead Sea.",
],
];
// Programmatically create a dataset in LangSmith
const dataset = await client.createDataset("Sample dataset", {
description: "A sample dataset in LangSmith.",
});
const inputs = examples.map(([inputPrompt]) => ({
question: inputPrompt,
}));
const outputs = examples.map(([, outputAnswer]) => ({
answer: outputAnswer,
}));
// Add examples to the dataset
await client.createExamples({
inputs,
outputs,
datasetId: dataset.id,
});
5. Define your evaluator
- Python
- TypeScript
Requires langsmith>=0.1.145
from pydantic import BaseModel, Field
from openai import OpenAI
openai_client = OpenAI()
# Define instructions for the LLM judge evaluator
instructions = """Evaluate Student Answer against Ground Truth for conceptual similarity and classify true or false:
- False: No conceptual match and similarity
- True: Most or full conceptual match and similarity
- Key criteria: Concept should match, not exact wording.
"""
# Define context for the LLM judge evaluator
context = """Ground Truth answer: {reference}; Student's Answer: {prediction}"""
class Grade(BaseModel):
score: bool = Field(description="Boolean that indicates whether the response is accurate relative to the reference answer")
# Run the application logic you want to evaluate
def chatbot(inputs: dict) -> dict:
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Answer the following question accurately"},
{"role": "user", "content": inputs["question"]},
]
)
return { "response": response.choices[0].message.content.strip()}
# Define LLM judge evaluator that grades the accuracy of the response relative to the reference output
def accuracy(outputs: dict, reference_outputs: dict) -> bool:
response = openai_client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{ "role": "system", "content": instructions },
{"role": "user", "content": context.replace(
"{prediction}", outputs["response"]
).replace(
"{reference}", reference_outputs["answer"]
)},
],
response_format=Grade
)
return response.choices[0].message.parsed.score
Requires langsmith>=0.2.9
import OpenAI from "openai";
import { z } from "zod";
import { zodResponseFormat } from "openai/helpers/zod";
import type { EvaluationResult } from "langsmith/evaluation";
const openai = new OpenAI();
// Define instructions for the LLM judge evaluator
const instructions = `Evaluate Student Answer against Ground Truth for conceptual similarity and classify true or false:
- False: No conceptual match and similarity
- True: Most or full conceptual match and similarity
- Key criteria: Concept should match, not exact wording.
`;
// Define context for the LLM judge evaluator
const context = `Ground Truth answer: {reference}; Student's Answer: {prediction}`;
const ResponseSchema = z.object({
score: z
.boolean()
.describe(
"Boolean that indicates whether the response is accurate relative to the reference answer"
),
});
// Run the application logic you want to evaluate
async function newPipelineAnswer(inputs: string): Promise<{ response: string }> {
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content:
"Answer the following question accurately",
},
{ role: "user", content: inputs },
],
});
return { response: response.choices[0].message.content?.trim() || "" };
}
// Define LLM judge evaluator that grades the accuracy of the response relative to the reference output
async function answerAccuracyEvaluator({
outputs,
referenceOutputs,
}: {
outputs?: Record<string, string>;
referenceOutputs?: Record<string, string>;
}): Promise<EvaluationResult> {
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{ role: "system", content: instructions },
{
role: "user",
content: context
.replace("{prediction}", outputs?.answer || "")
.replace("{reference}", referenceOutputs?.answer || ""),
},
],
response_format: zodResponseFormat(ResponseSchema, "response"),
});
const parsedResponse = ResponseSchema.parse(
JSON.parse(response.choices[0].message.content || "")
);
return {
key: "accuracy",
score: parsedResponse.score,
};
}
6. Run and view results
- Python
- TypeScript
# After running the evaluation, a link will be provided to view the results in langsmith
experiment_results = client.evaluate(
chatbot,
data="Sample dataset",
evaluators=[
accuracy,
# can add multiple evaluators here
],
experiment_prefix="first-eval-in-langsmith",
max_concurrency=2,
)
import { evaluate } from "langsmith/evaluation";
// After running the evaluation, a link will be provided to view the results in langsmith
await evaluate(
(exampleInput) => {
return newPipelineAnswer(exampleInput.question);
},
{
data: "Sample dataset",
evaluators: [
answerAccuracyEvaluator,
// can add multiple evaluators here
],
experimentPrefix: "first-eval-in-langsmith",
maxConcurrency: 2,
}
);
Click the link printed out by your evaluation run to access the LangSmith Experiments UI, and explore the results of your evaluation.
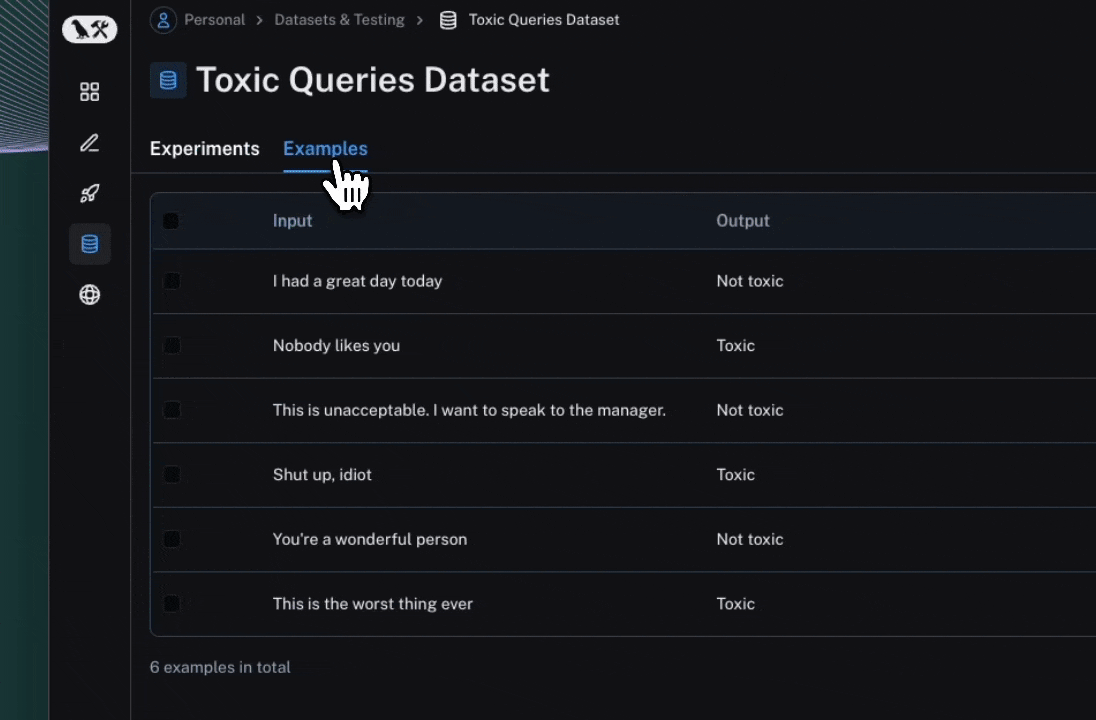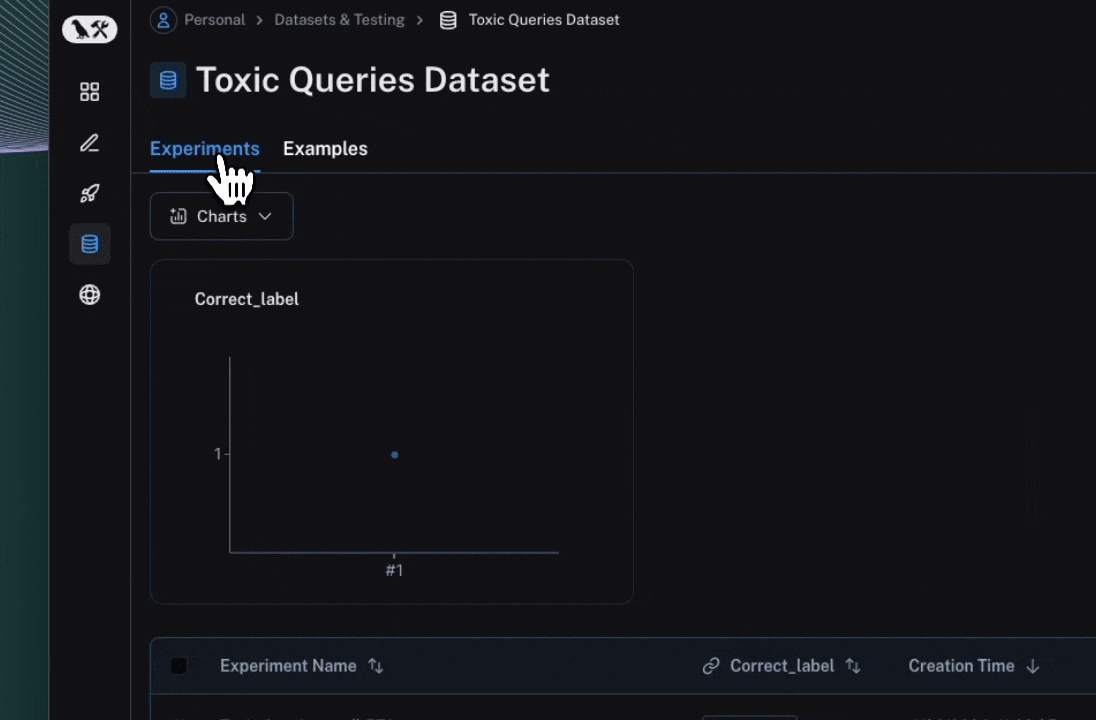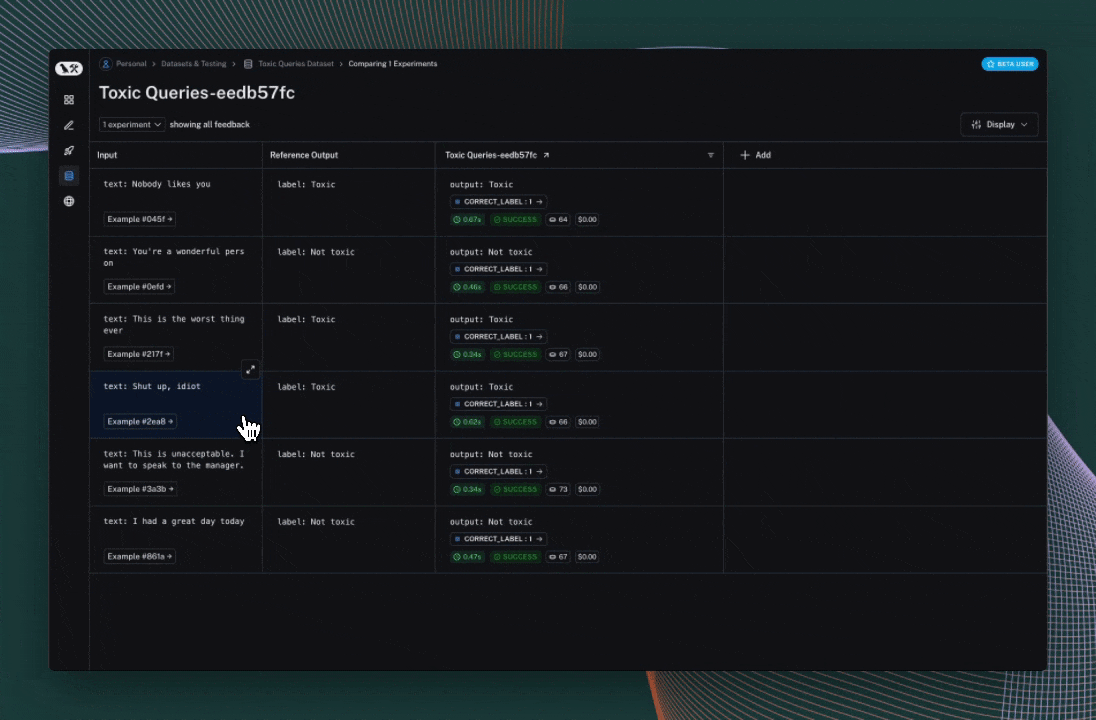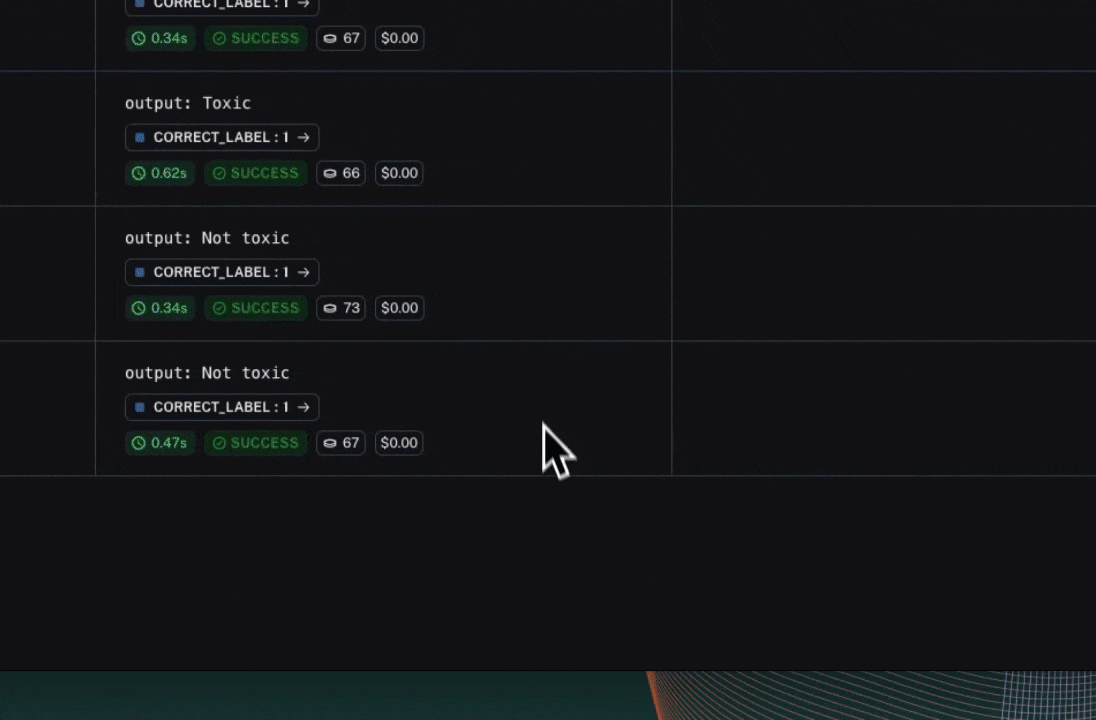
Next steps
For conceptual explanations see the Conceptual guide. See the How-to guides for answers to “How do I….?” format questions. For end-to-end walkthroughs see Tutorials. For comprehensive descriptions of every class and function see the API reference.